The ability to ingest does not make you intelligent – REStream Announcement
The functionality of REStream including a newly introduced free tier is available in UTStream starting with release 2.0. Go check it out now on Splunkbase!
Dealing with large amounts of log data is a challenge for enterprises of all sizes. The two main cost drivers are licensing fees for Data Analytics tools like Splunk™ or Elastic™ and ever-growing storage requirements. As soon as the license is increased to allow for ingestion of additional data, the storage gets full, and even further investments are pendent.
Most log data available in a Data Analytics Tool never gets searched and is only kept for compliance reasons and insurance for potential future issues. Why store all this data in an expensive, high-maintenance, and resource-intensive system?
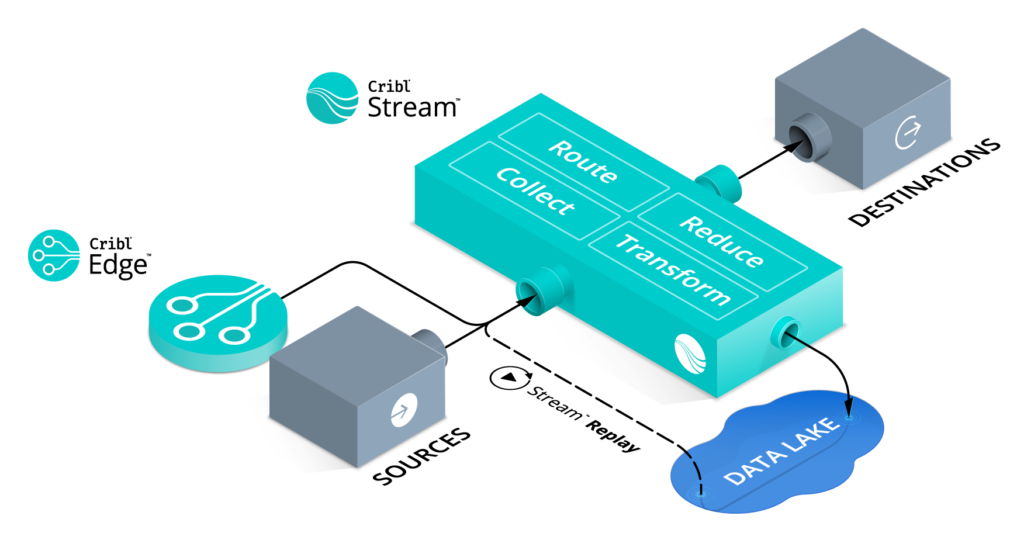
Cribl Stream™ is a joker in all cases where logs need to be stored without being searched in the next few hours after ingestion. Instead of sending log data to a system like Splunk, all records are sent to Cribl Stream and processed by its might data transformation and routing functionality.
A New Hope
Let us do a mind game! Imagine being the observability responsible for a large enterprise with a 20TB raw log data daily ingestion volume and using Splunk Enterprise™ and the accompanying Splunk Enterprise Security™ SIEM solution. As your enterprise is handling credit card data, you have to ensure a minimum retention time of one year:
Daily ingestion volume: 20TB Daily ingestion volume compressed: 10TB Total yearly storage volume: 365 * 10TB = 3650TB Search Factor = 2 5Replication Factor = 3 Total storage required: 3650TB * 0.35 * 2 + 3650TB * 0.15 * 3 + 20TB * 3.4 = 4266TB Count of Indexers: 200 Storage per Indexer: 4266TB / 200 = 22TB
Out of all the data ingested into Splunk Enterprise, roughly 60% are CIM compliant and actively used by Splunk Enterprise Security. This means you store approximately 1.7PB of log data just “in case”.
Your boss decides to implement Cribl Stream and only send logs to Splunk Enterprise required by the currently active correlation searches. Furthermore, your boss heard of the Replay feature available in Cribl Stream that allows replaying logs into Splunk. Therefore the retention time in Splunk gets reduced to 90 days for immediate analysis cases as required by PCI DSS. Logs for the remaining 275 days are stored in an observability leak by Cribl. Let us redo the math and see what this means for you:
Daily ingestion volume: 12TB Daily ingestion volume compressed: 6 Total yearly storage volume: 90 * 6TB = 540TB Search Factor = 2 5Replication Factor = 3 Total storage required: 540TB * 0.35 * 2 + 540TB * 0.15 * 3 + 12TB * 3.4 = 662TB Count of Indexers: 200 Storage per Indexer: 662TB / 200 = 3.3TB
With all these changes, your license usage is reduced by 40% and required storage by 85%!!! In addition, your indexers can be consolidated, and the total number of required indexers reduced significant.
But what about the logs? Are they now stored in the void or what? No, of course not. Cribl Stream stores all records it receives compressed and in original form in an S3 compliant bucket. Logs are discoverable and can be replayed into Splunk on demand. We require roughly 74TB of S3 space, assuming a compression to 10% of the original size.
The SOC Strikes Back
Success! Cribl Stream is implemented, and everything keeps working as before the change. The SOC did not notice the difference (even though you involved SOC in all aspects of Cribl Stream). A few days after the change, you get a sharp ping from one of the Senior Security Analysts who does not find the data they always had to investigate a notable. As kind as you are, you log in to Cribl Stream and replay the files the Analyst requires. But already, you foreshadow that there might be a lot of this kind of request sliding into your DMs.
Return of REStream

Involving a Cribl Administrator to Replay logs stored in S3 storage is not feasible as this produces overhead and delays. The Splunk™ Add-On for Cribl Stream Replay, or better known as REStream, solves this challenge and allows all Splunkers to become a Replay master without any midi-chlorians. REStream provides interactive dashboards in Splunk to control all aspects of Cribl Stream Replay. The add-on can be used with complex Cribl Stream installations as it handles distributed environments and even multiple Cribl Stream installations concurrently.
Discovery
The Discovery Feature of the Cribl Replay add-on allows a Splunker to discover the data available in S3. For this, the Splunker needs a time range, an index, source and host. Of course, wildcards are supported, and discovery jobs can span many files.
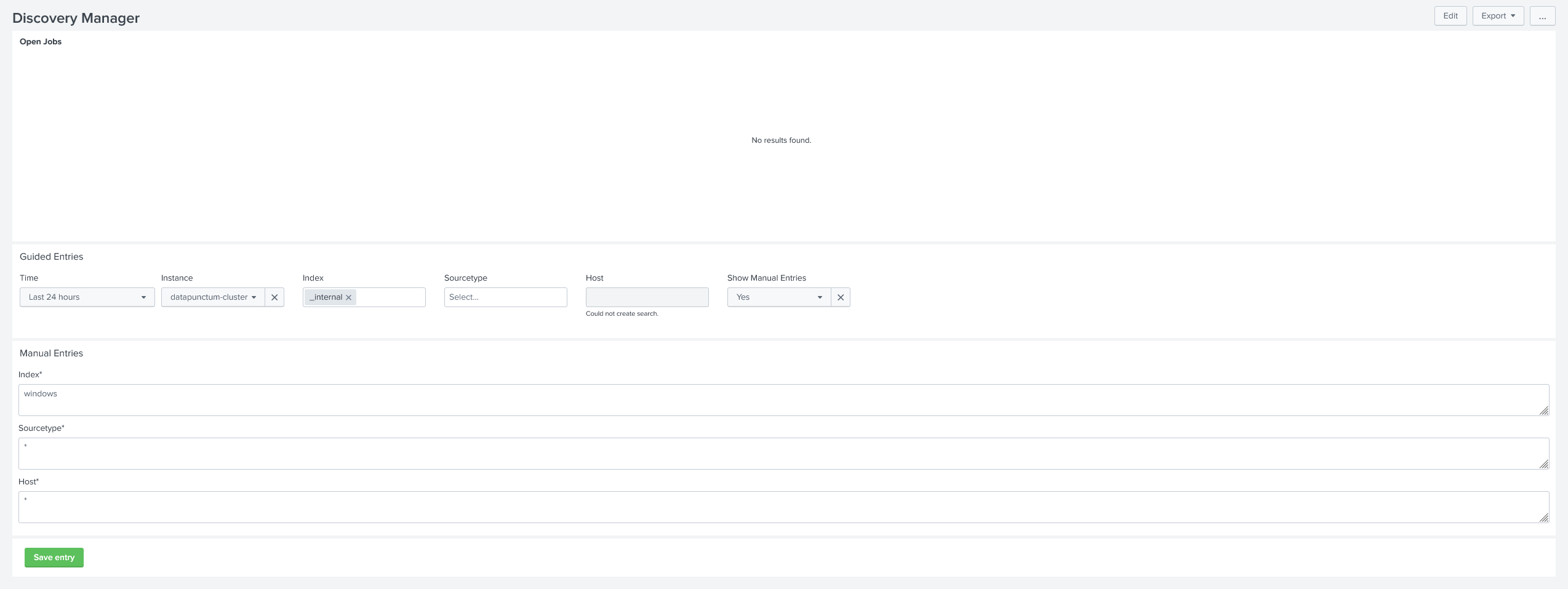
Once a discovery job has been completed successfully, all files discovered are matched with files already replayed by the Cribl Replay add-on and stored accordingly. Based on the discovery results, a Splunker can select distinct files or replay many files at once, guided by a distinct, easy-to-use dashboard.
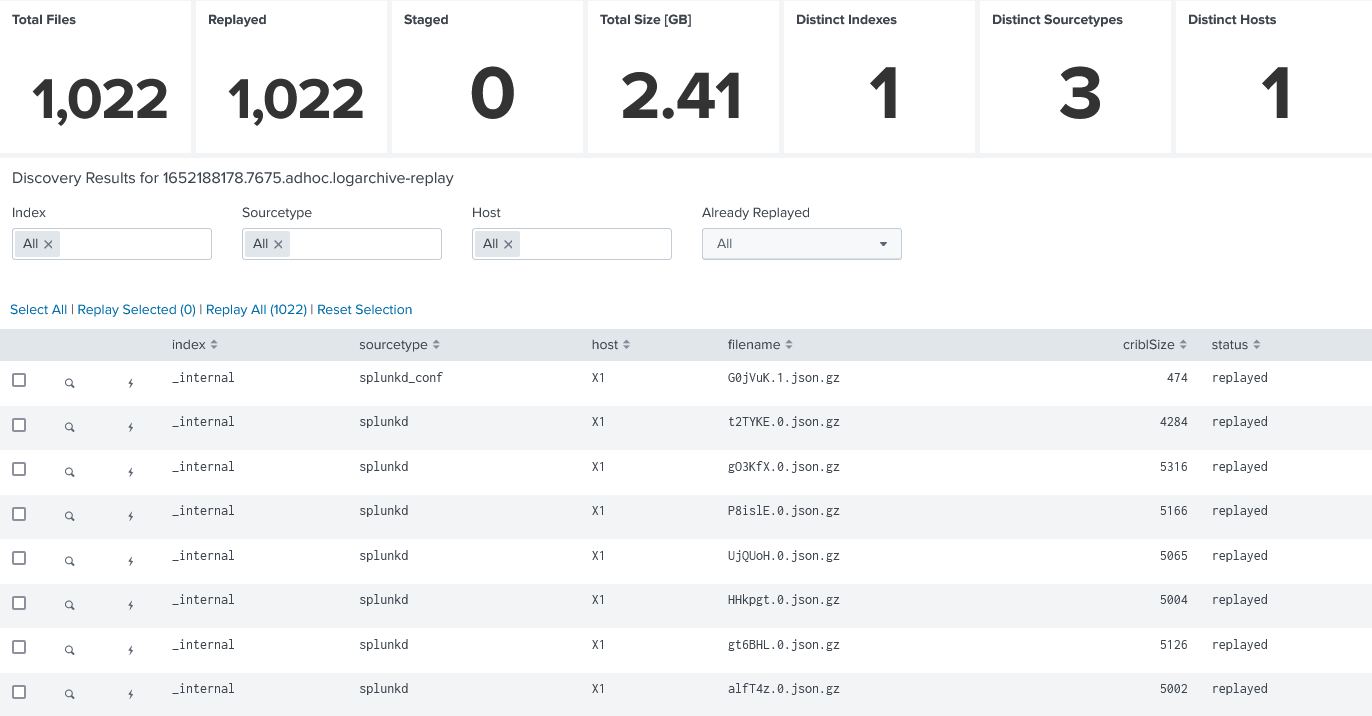
Replay
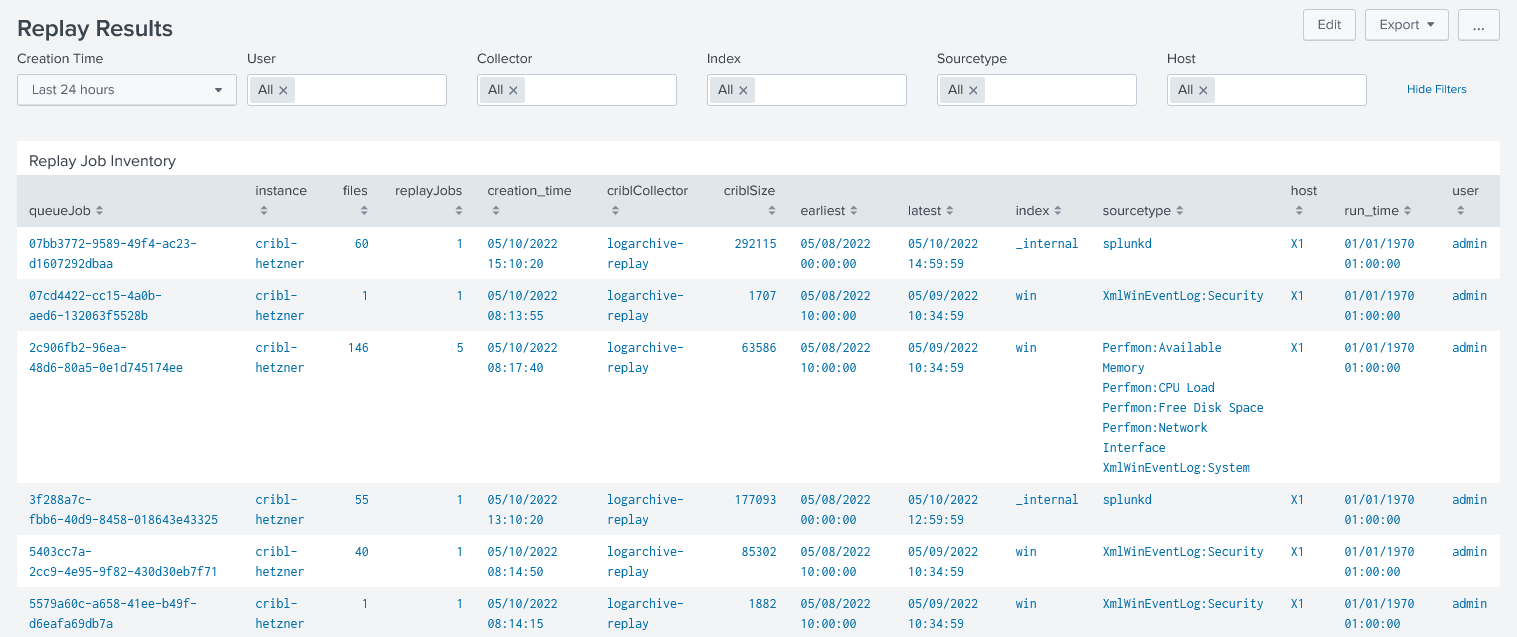
All discovered files are available for Replay. In a replay job, up to many files are read by Cribl Stream from S3 and sent to Splunk using the Splunk TCP protocol. Therefore all index time operations are done as usual. The add-on checks for every file if it is already replayed and prevents duplicates.
Preview
An essential feature of Cribl Stream Replay is allowing the user to preview a file before sending it into Splunk. The preview feature is available for discovered files. Cribl Stream reads the file to preview, and up to 100 logs are visible in Splunk.
Automated Replay
To take even more interaction of the Splunker the add-on ships with a modular alert action that allows for a fully automated replay of logs stored in S3. The alert action requires the search to provide an index, sourcetype, host and timespan. Subsequently, the alert action discovers and replays all applicable files.
The Rise of your Data Analytics Stack
Contact us at apps (at) datapunctum.ch for any questions regarding Splunk™, Cribl Stream™ or REStream and get started with your journey to full control over your log data today! Because, as you know, storage space is built on hope!